Usually people share their knowledge about monads right after they get to
understand them. I decided to share my experience with monads when a friend of
mine started studying this topic. So here it is - my trip into monads.
In this blog post I’m not going to give you the exhaustive list of all monads,
or explain the theory behind monads. I’m going to share with you the example
that I used to develop intuition about monads.
Let’s solve the following problem. We are going to build a library for parsing
different values from a string. For the sake of simplicity we are going to
build two functions. One function parses a number delimited by whitespaces. The
other function will be parsing a string delimited by whitespaces. I’m going to
illustrate what monad is in Go. Our Go will be a slightly special flavor of Go.
It will have genercis. However all the idioms that I demonstrate here are
imported from Haskell.
In this exercise let’s imagine that Go is a purely functional language. You
can’t use any imperative constructs in our version of Go. With one exception
though. Consecutive assignments are allowed. Those are not imperative
constructs. Also our Go will have two features: generics and tuples. As a
result half of the code here won’t compile in Go. This code can be successfully
rewritten in Java and compiled. But I decided to go with the modified Go
instead of Java because of Go’s brevity.
Let’s declare the type of our first function. The function that parses a string.
This function will be accepting an input string and returning the result and
the remaining string.
ParseInt will look very similar. It can even use parseString except it will need
to convert the result to int.
parseInt
12345
funcparseInt(sstring)(resint,remstring){resString,rem=parseString(s)res,_=strconf.Atoi(resString)// we are ignoring error for the simplicity of the examplereturnres,rem}
Now let’s write a function that is supposed to use our two functions. It will
parse an integer and a string from the provided input string. It will also
return the remaining string.
Now, people who were implementing it for the first time in Haskell noticed that
there is a repetition in this code. We pass the remainder of the previous
parse function and pass it into the next one. They decided to abstract this
repetition into a separate data structure. Let’s declare a new structure.
Parser Type
1
typeParser<V>func(sstring)(vV,sstring)
Now let’s change the signature of our parse functions a bit:
funcparseInt()Parser<Int>{returnfunc(sstring)(int,string){resString,rem=parseString(s)res,_=strconf.Atoi(resString)// we are ignoring error for the simplicity of the examplereturnres,rem}}
At this point we need to define another interface that our Parser is going to implement:
What it does it return a function that is a chain of two functions together. Function p
and function f. Bind method just takes two functions and composes them into a bigger function.
The implementation of our example now turns into the following:
Here we encounter another method of that every monad should implement - lift. In Haskell this method is called return, but I decided not to use this name in order to avoid
confusion with the built in return. Here is the implementation of lift.
What we implemented here is called state monad. For me it was the hardest monad
to understand. I hope this blog post helps you in your understanding of monads.
Authors of some blog posts on the Internet deprive software engineering of the
right to be called an engineering discipline. They like to give examples of how
accountable and responsible real engineers are and how reckless are software
engineers. As a person who spent 7 years in university learning different areas
of math in order to become a software engineer I find those statements
preposterous and insulting. At the same time I have to admit that a lot of
practices that I see in the industrial software engineering give some ground to
those statements. I arrive to a conclusion that even if software is an
engineering discipline not everyone practices it as such.
After ten years in the industry I’m disappointed by how things are usually
done. The experience that you gain doesn’t elevate you. You keep running into
the same issues that you need to troubleshoot over your weekend. There is no
tradition to follow the principles of design that would allow developers to
avoid those mistakes. Andrew Hunt and David Thomas discuss these principles in
their book Pragmatic Programmer. I’ve never seen those principles applied
consciously in practice. Notorious user’s convenience drives design processes
instead of mathematical purity. For some reason developers assume that their
software will be used by brainless monkeys.
Software developers can decide to use a library without fully understanding the
characteristics of the library. It’s unheard of in any other engineering
discipline to use a material with unknown parameters.
Software is one of the most complex systems we’ve ever dealt with in the
history of mankind. The horizon of available programs and libraries constantly
expands. In these circumstances programmers are forced to deal with
uncertainty. Writing a new piece of software is like sending a moon probe.
Every time we argue whether the Moon is solid.
Fashion and market opportunity drive design decisions. The industry is not set
up to make conscious decisions. We have many products with similar
characteristics. Software community keeps creating new versions of the same
thing introducing the same problems.
Why do we have five different databases?! Every new database claims to be
better than all previous ones. After building the new database its developers
create connectors to old databases. They want to be a part of the community.
Otherwise the inertia will spew them. From outside it may look like conspiracy
theory. Programmers create jobs for themselves. Companies waste their resources
picking among all possible options or maintaining all of them.
In these cases I like to say that there is no need to look for conspiracy where
you can explain everything with negligence. Instead of creating five databases
or even creating one highly configurable database we need to create medium
sized components that allow us to quickly construct any of those databases.
Every creator of a new database who realized another use case
where the database can be useful should go back and break existing databases
into smaller pieces with his new understanding of the domain and build his new
database with some more approaches.
Every creator of a new database should go back, break existing databases into
smaller pieces, and construct his database from those pieces. This approach may
not be the fastest for him. But it will pave way for the future database
builders. They will have components more suited for constructing for databases.
Of course no venture capitalist will fund years of refactoring of old databases
in order to build another one in one day.
In this situation I see open source as the solution to this issue. Only the
users of the software themselves can build the right tool. They won’t care
about marketing their tool. They will use this tool themselves. They know what
they need. It makes the process of software development very similar science.
Unlike what software engineering does to programs, science refines and expands
its theories. Many people tend to compare software engineering to manufacturing
process. I find this comparison inaccurate. Software engineering is more like
design process.
In manufacturing you need to create blueprints specific to the manufacturing
line. Similar parts need to be redesigned for different manufacturing lines.
Software engineering has this unique ability to reuse blueprints without
implementing them in the physical world.
In software engineering every blueprint is already a product. This product is
very malleable. As such, it doesn’t make sense to create another blueprint if
you already have one. You need to go back split the initial blueprint, pick the
parts that you need, complement with missing part, and ship your new product.
You product will consist of parts of old blueprint and new blueprints.
In science we add layers of knowledge on top of existing layers. We restructure
existing knowledge, but we never recreate existing concepts. Nobody has several
implementations of Newtonian physics where gravity works slightly different in
different implementations. Software engineering should employ similar approach.
Reusable implementations of existing algorithms that can be assembled into
anything we want like Lego bricks.
Modern programming languages are a break through in this area. But we still
have a huge gap between the abstractions that modern languages provide and
library primitives. Languages give us too small abstractions. Libraries give us
too big abstractions. The great number of different languages only inhibits the
formation of this middle layer.
So, let’s start picking our tools and libraries carefully without creating
redundancy. Let’s tear existing tools apart in order to create new tools from
those parts. Those smaller parts in their turn can serve somebody else in their
projects.
And we need to have one language that is truly universal. We don’t have such a
language yet. This language should produce truly composable primitives. So far
it looks like Haskell is the one. Though the language research is still in
progress.
I’m happy to report that in recent years great software with focused purpose
started emerging. I would like to endorse suckless tools. They provide truly
reusable pieces of software. Xmonad and similar minimalistic window managers
perfectly complement suckless tools. These programs allow you to build desktop
environment that can evolve with your understanding of efficient workspace.
Unix philosophy is another great example of how composable programs can be built.
It looks like there is a way. We just need to try harder.
I’ve come to understanding that most people organize things like if they were
disassembling a car: 5 inch screws in one pile, 3 inch screws into another
pile, nuts in a third pile, etc. This is the approach that comes first to our
mind when we need to organize something. However it’s not the easiest way to
make sense of the whole system if it’s structured this way. The whole system
looks like several boxes with nuts and screws of different shapes and sizes.
Another way to do it is by structuring the whole system as interacting
entities. Screws and nuts from engine go into one box. Parts for suspensions
system and wheels go into another box. This way we see functioning elements
instead of piles of smaller parts.
Let’s discuss each of the approaches in details below and with some examples.
In this context let’s think about the whole system and several entities standing
side by side or as a tree of objects. A good example would be a row of people.
The first approach I call horizontal, the second - vertical.
Horizontal Slicing
The first approach thinks about this row of people as several buckets: one
bucket with heads, one bucket with hands, one bucket with bodies, one bucket
with legs, and one bucket with feet. Not only imagining it is unpleasing it’s
also disfunctional. Parts in each of those buckets have very little, so called,
cohesion. They
don’t interact with each other. They are useless. They just lie in those piles.
This obviously preposterous structuring in this context finds surprisingly wide
support in software engineering. People create a separate package for
exceptions, a separate package for utility classes, etc. Also instead of
sealing logic inside of one class it gets spread among several classes. This
approach leaves little room for encapsulation. Classes and packages have to
make every its member public, because everyone outside this package or class
needs to interact with their members. Setters and getters are considered the
summit of encapsulation
in such an environment.
The only argument in favour of this approach is that it’s obvious how to use
it. It may have place if these moving parts are already in a relatively small
box. One box for engine and then smaller boxes inside this one for engine’s
screws and nuts.
Vertical Slicing
The other approach I would call vertical slicing. Vertical because it thinks
about a row of humans as several buckets - human one, human two, human three.
These bodies can’t interact with each other by any means other than defined by
public interfaces for these bodies. The liver of one body doesn’t interact with
the heart of another body.
Thinking about your classes and packages as living creatures rather than
a buckets for screws and nuts helps a lot with encapsulation of the classes.
The internal state of those classes can be hidden by conventional java’s
access control modifiers.
If all the moving parts of one entity are colocated in the same package it’s
easier to find them as you are reading the code.
Each package or class in this approach should be as a small library that
provides functions and has a public interface. When I’m writing code using this
approach I’m asking myself whether I can extract this package into a library
right now. Once I actually need to extract a library from the project is easy
to do so.
Other Areas
It’s interesting that this idea is also applicable in other areas of software
engineering. Scrum advocates for vertical slicing of teams. Scrum teams are
supposed to be cross functional and cut through all layers of the product, so,
that one team can deliver any functionality. It’s also a popular tendency to
slice teams horizontally. It leads to enormous amount of dependencies between
teams and chaos when delivering a feature that has parts in each of the layers.
Examples
Let’s take a look at some of examples when the choice between these two
approaches is not particularly obvious, but very important.
AST Translation
A perfect case when people get easily confused how to group classes in packages
is translation of an AST. If you have an application and different parts of
it need to translate this tree into different things then you naturally get
an interface for Visitor for this AST. The tendency to put alike with alike
leads to a confusion. Should implementations of the Visitor interface be stored
near AST definition or near the services that use these implementations.
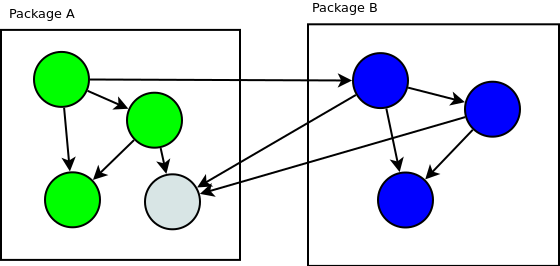
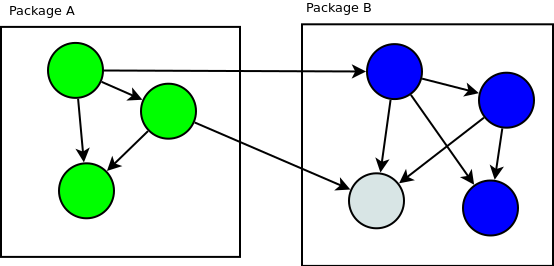
When this question arises I’m thinking about the dependencies that each class
has on other classes as lines between classes.
When we move classes from package to package we want to minimise the number of lines
crossing the boundary of packages.
Three dependencies go through the boundary.
Two dependencies go through the boundary.
In this particular case thinking about this AST tree as a library helps a lot.
The interface Visitor should be stored near the AST tree structures in a
separate package and the implementations of this Visitor interface should be
stored where they are used. It also minimizes the number of dependencies going
through the boundary.
Configuration Beans in Spring
Engineers also tend to put all bean declarations in one configuration bean at
the top level of their applications. Here I can say that if the classes inside
the package don’t rely on IOC container then it’s a perfectly normal practice,
because they don’t depend on the defined beans and the main application considers
these classes as plain java objects.
However if the classes inside the package expect some IOC container to be in
place then it makes sense to put another configuration class inside the package
because it helps with understanding how classes will be wired together.
P.S.
After writing this post I google on this topic and found surprisingly many
similar posts:
Builder pattern seems to be one of the most versatile patterns of all
creational patterns. Its role is usually underestimated and it usually goes
unnoticed among other easier for understanding creational patterns: Abstract
Factory, Singleton, Prototype. Further I suggest to review some of
variations of Builder pattern. In certain cases the variations bring
the pattern closer to Visitor pattern. In other cases the modifications bring
it closer to Abstract Factory pattern. Nevertheless the way it is used stays the same.
All the variants give us fine tuned control over the dependencies and modularity
of the code where the Builder pattern is used.
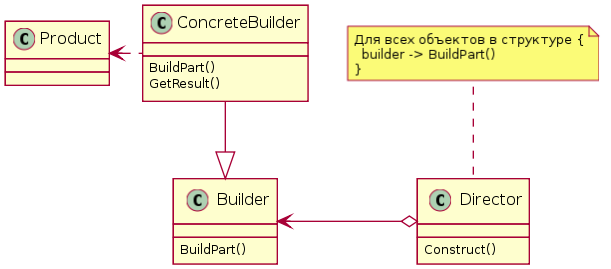
Classic Description
Builder pattern is widely known from the book by Gang of Four[1]
Builder pattern separates the process of construction of a complex object from
its representation. So that the outcome of the same process of construction
can be different.
Classic applications of builder pattern is presented on the class diagram
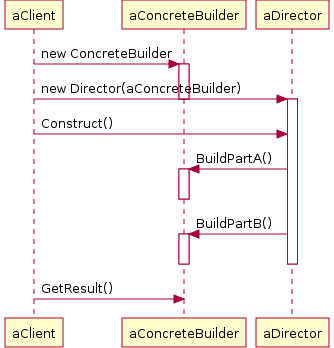
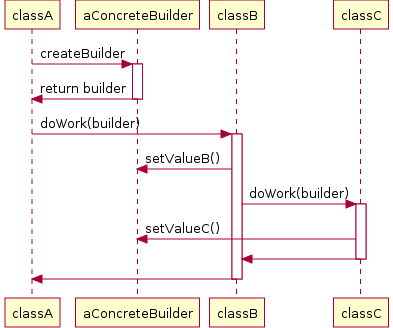
Sequence diagram
illustrates the relationship of builder and director with the client. This
variant of Builder pattern can be used in a code that is responsible for
building charts of arbitrary format:
123456789
class PriceData {
Map<String, Integer> data;
public void buildChart(ChartBuilder chartBuilder) {
for (Map.Entry<String, Integer> entry: data.entrySet()) {
chartBuilder.addKeyValue(
entry.getKey(), entry.getValue());
}
}
}
In this case the main application will be a client. The collector of the data
for the diagrams will be a director. The construction of concrete charts(pie
chart, histograms, line chart) will be done by a concrete implementation of
builder - a class implementing ChartBuilder. This usage allows us to abstract
out the process of construction from the concrete implementation of the object
being constructed.
Modifications of The Pattern
In common practice we can encounter modifications of Builder pattern that
allow us to manage dependencies inside the project in various ways. The
modifications fall into different categories based on the location of
GetResult method call and on the number of directors.
Location of GetResult Call
Variations of Builder pattern can be classified based on the location of
GetResult call. GetResult method can be called either from the director or
from the client.
Invocation From Client
If GetResult method is invoked from the client then this variant is for
abstracting out the director from the implementation of resulting object as
it’s represented in the classic case.
Invocation From Director
In this case the result is required by the director itself, but the director
doesn’t know the implementation. If the client doesn’t invoke set-methods of
the Builder then this implementation of Builder pattern can be replaced with
AbstractFactory. In the case when a part of the director should be configured
before passing it to the director AbstractFactory is not suitable because it
focuses on synchronous object construction. In this case Builder pattern is the
most suitable option.
12345678910111213
class ClassProcessor {
public main() {
builder = new ExprProcBuilder();
builder.setClassFields()
methodProcessor.processMethod(builder);
}
}
class MethodProcessor {
public processMethod(ExprProcBuilder builder) {
builder.addLocalVars();
builder.buildExprProc()
}
}
The Number of Directors
Variations of the pattern can also be defined by the number of directors.
No Directors
There may be no directors. In this case Builder pattern is used as a constructor
with named arguments. Client and director are the same entity.
One Director
If there is one director then it leads us to the classical variant of Builder
pattern for abstracting out the product construction from its concrete
implementation.
Several Directors
There may be more than one director. Everyone in the chain of directors sets
the parameters that it knows about and passes the builder to the next director.
This variant of Builder pattern reminds more of Visitor pattern. Pattern
Visitor is usually used for handling Composite pattern. In the case of
Builder pattern the visited objects can have arbitrary nature. Here is an illustration
of the case with several directors:
Features of The Pattern
Inversion of Dependencies
One of the main reasons to use Builder pattern - inversion of dependencies. The
builder is passed to a director during construction, what ensures isolation of the
director from the implementation details of concrete builder.
Named Arguments of Constructor
Another reason as it’s specified in [2] to use Builder pattern can be a lot
of arguments of the class being constructed. Let’s take a look at a piece of
sample code.
1
new Builder().setA(value1).setB(value2).createProduct()
From this code it’s clear that value1 becomes A in the new product, and
value2 becomes B. It allows us to change the order of arguments in the
invocation. Named arguments make the code more readable. The invocation of
method GetResult is done by the director itself, which is also a client.
Builder’s role here is similar to the role of AbstractFactory pattern, but
unlike AbstractFactory pattern, who’s task is to give access to construction
of construction of a group of connected objects, Builder is focused on
construction of instances of only one class.
Decomposition in Time
This pattern also allows us to configure builder as we receive data necessary
for configuring it. So the construction can lapse in time instead of happening
at once as it’s done in factories or constructors. Builder pattern tracks the
consistency of the object being constructed and if some of the arguments are
missing it can throw exceptions or execute any other action required to inform
about the incomplete state.
Loosening Coupling
This approach also allows us to loosen coupling between classes. Each class can
set only the arguments this class is aware of and pass the builder further in
the chain of construction. The classes only need to know about the structure of
the builder and don’t need to know about each other. They also only work with
the methods they need to know of and don’t need to care about the rest of the builder.
This usage of Builder pattern makes it very similar to Visitor pattern.
Then method GetResult can be invoked when the builder is returned back
to the client from the chain of invocations inside directors(in the beginning
of the chain) or by the final director(end of the chain).
Tolerance for Change of Data Format
If Builder pattern is used as in sections Loosening Coupling and Several
Directors then if we need to collect more data we can use new methods only
where they are required keeping the rest of the chain of directors intact.
Instead of getting data through get methods sometimes it’s more flexible to
pass Builder pattern.
Example
Let’s illustrate what we described above in the case for several directors.
Method GetResult can be invoked by classA as well as by classC. In both cases
classA and classC can’t know anything about each other’s dependencies, what
reduces dependencies of each of them, but gives them access to the required
object. In addition to that classC receiving partially configured, can change
only the part he knows about and as a result receiving different objects
depending on the requirements.
The latest approach is particularly convenient, when the client class requires
different instances of a class depending on the data that client class has,
but IOC container restricts access to constructors.
Conclusion
Builder pattern is a sufficiently powerful and flexible instrument for
dealing with dependencies inside a project and inversing the dependencies.
Regrettably, the usage of Builder pattern requires writing a lot of
boilerplate code. It complicates effective usage of this pattern in modern
programming languages.
As Rob Pike appropriately mentioned in his presentation at OSCON 2010: patterns
- are usually solutions whose implementation is missing from the language. We
can only hope that working with builder pattern in future languages will be as
simple as just writing a constructor.
Appendix A
Appendix B
Appendix C
Bibliography
Erich Gamma and others. Design Patterns: Elements of Reusable Object-Oriented Software, 395 p.
Bloch J. Effective Java. Second edition. Prentice Hall, 2008.
I started my long path into the world of computing in norton commander. Then I
worked in windows 3.11 and windows 95 all windows through windows 2003, windows
xp. In parallel I was introduced to linux. Initially the only interface I saw
in Linux was pico commander. Then all the associates of xwindow system showed
up - gnome, kde, xfce.
The evolution of interfaces that I learned was from command line to graphical
interface. The introduction of graphical interface seemed to be a progress.
The introduction of touch screen interfaces that came with the advent of iphone
era produced even more confusion. Around that time I graduated from university
and started working in enterprise as a java programmer.
During my 5 years at the university I participated in ICPC. ICPC is an
international competition in programming. You have three people behind one
computer and 8-12 programming problems to solve. First two years we were
programming in Pascal. Third year we programmed in C++ and then moved to Java
and eclipse as an IDE. Java seemed like a progress. Intelligent autocompletion
in Eclipse completely blew my mind. Most of the time we weren’t typing - we
were tapping ctrl-space and the IDE seemed to have been writing code for us.
Every winter and summer we used to go to programming camps in Petrozavodsk. To
one of those camps a team from Poland was invited. They were very strong and
they were programming C++ in … Vim. This discovery completely threw me off.
It was completely unclear to me why they would use Vim. Vim seemed to be
something ancient, completely unfit for our twenty first century. I never
bothered to spend too much time researching this phenomenon, but it definitely
struck me, and I had remembered it.
So, when I went to enterprise I was completely confident that I used the most
advanced technologies for programming. After a couple of years in the industry
I got interested in Vim. It was the only editor available over ssh that we used
for programming on remote dev boxes. I had heard the editor was good and I
decided to give it a try. So I had been merely playing with Vim until I
attended a talk by one of our colleagues - Kirill Ishanov. His introduction to
Vim flipped my world. At that time I hadn’t realized all ramifications of my
discovery. Now I can tell you what impressed me - Vim was an interpreter of
text editing language. Every keystroke in command mode is an instruction in
this language. If you want you can put those instructions in a register and
execute them in a batch. It’s called macros. You can record macros by entering
commands and specifying what register you want to store them in or you can just
copy a sequence of letters into this register. Then the whole program would be
replayed from this register. That was the moment when I became an ideological
proponent of vim. Vim wasn’t just an editor. It was an interactive text
processor.
Now, getting back to java programming language. At the time when I was
programming in java I was under impression that all languages should be or are
like java - some variation of c like syntax, imperative in its nature. It
seemed normal to write code in an editor, then it would be compiled and
executed. Another thing was execution. We used Far manager(clone of Norton
Commander) to run our apps. We rarely typed commands in the command line.
Command line seemed like something old fashioned. We didn’t see point to use
it. At some point we started using it only because it was the only way to
communicate to a remote computer over ssh. We didn’t like it. It seemed like a
limitation of our abilities. I had had this attitude for command line until I
visited the US for the first time. Engineers at the US office were programming
in vim and were using command line like it was their editor for entering small
programs. I was impressed. I started learning how to use command line as
fluently as they did. Though I couldn’t realize the implications of this
discovery until I learned the third missing piece - powerful language with
expressiveness of python and strictness of java. Before I found this language
my understanding of command line was that it should have weird syntax. Haskell
completely rocked my world. Its command line allowed me to find out functions'
types which served as a good documentation. Most of the time I could infer what
functions were doing just based on their name and types. Declarative style of
functional programming worked very well with interactive interpreter. Instead
of giving instructions you were describing what you wanted to get.
This was when I realized that this idea should be taken to the extreme -
communication with a computer should happen inside a language interpreter.
Communication with your fellow programmers should be done through code. Code is
the ultimate way to communicate exactly what you want your computer to do.
Every time I hear someone saying that I they’ve achieved something on their
computer without writing code and that they avoid writing code because writing
code is erroneous it means they just didn’t realize that they wrote a line of
code. If you don’t program your computer it means instead of putting your
commands for the computer in a batch and executing them, you execute them
yourself without recording what you’ve done. It’s even more error prone. It’s
much harder to improve this way because now you need to remember what you’ve
done last time and you need to be diligent enough to repeat it precisely again.
Why bother remembering if you can just record your commands and work with them
in a text editor? Text and language are the tools of thousands years old. They
are the best so far to communicate information. Visual information, gestures
are the most effective. But if you want to preserve your knowledge for some
extended period of time then text is the most compact way to do so.
If you write code then you record all the steps that you are about to make. You
can analyze what you are about to do. You can version your code in the most
convenient way that is currently known - version control systems. Also compiler
can help you analyze what you do. Even if you use your computer in an
interactive way then using command line allows you to extend your vocabulary of
commands. You can recall previous commands and reuse them even if you never
bothered to add them to you standard library of commands. Computer is a machine
that is built to execute commands.
Writing code is the best way to interact with your computer if not the only one.
Pomodoro technique is a useful time management technique. There have been
written a lot about pomodoro technique ever since it was published by
Francesco Cirillo in the late 1980-s.
The technique recommends using a mechanical timer for measuring time. There are
several reasons for using a mechanical timer: ticking timer reminds about
pomodoro in progress and presumably boosts focus.
Conventional kitchen timers are very nice, but they are not particularly
convenient for office environment. They are ticking, and their ringing is too
loud and very difficult to adjust. There are many apps for pomodoro technique
timer, but I’ve always wanted something that satisfies my requirements and has
a physical button rather than a virtual one. I tried retrofitting existing
timers and toys. It turned out to be easier to build an electronic timer. It
also looks very techy.
You can find the eagle project files
here. I used oshpark
community order for PCBs. You can order this PCB
here The firmware is available
here I used sparkfun
USBtiny ISP to program it.
The timer has five binary positions for displaying remaining minutes. It also
has LEDs for busy and available mode. You can tell your colleagues that if the
light is red then you are busy. The timer goes off with an audible beep. The
whole system is designed the way that you can use arduino IDE to compile the
firmware and program the device.
This is the synopsis of the second Linux programming lab.
The assignment for the second lab
The second assignment is to write a program that prints words which are
combinations of all characters of an alphabet. The combinations should have
certain length. For example, if length of the words is 3 and the alphabet is
“abc” then all possible combinations will be
123456789101112131415161718192021222324252627
aaa
aab
aac
aba
abb
abc
aca
acb
acc
baa
bab
bac
bba
bbb
bbc
bca
bcb
bcc
caa
cab
cac
cba
cbb
cbc
cca
ccb
ccc
Naive solution
Here is the easiest solution to print a list like this one above:
However this solution has a significant limitation. We can’t get words of
arbitrary length. Recursive bruteforce can overcome this limitation.
Recursive bruteforce
recursive bruteforce
12345678910111213
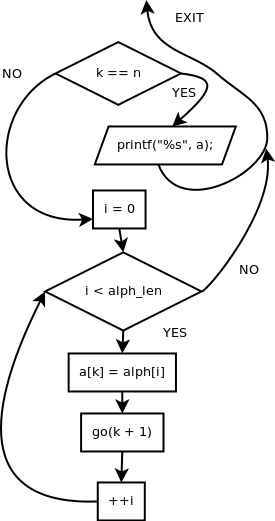
voidgo(intk){if(k==N)// N - length of the word{printf("%s\n",a);return;}for(inti=0;i<ALPH_LEN;++i){a[k]=alph[i];go(k+1);}}
Invocation of go from the main function looks like this:
recursive bruteforce
1
go(0);
The flowchart of the go function is presented below.
Recursive brute force can be regarded as a process of spawning a copy of the
same function and entering it again with storing the current position.
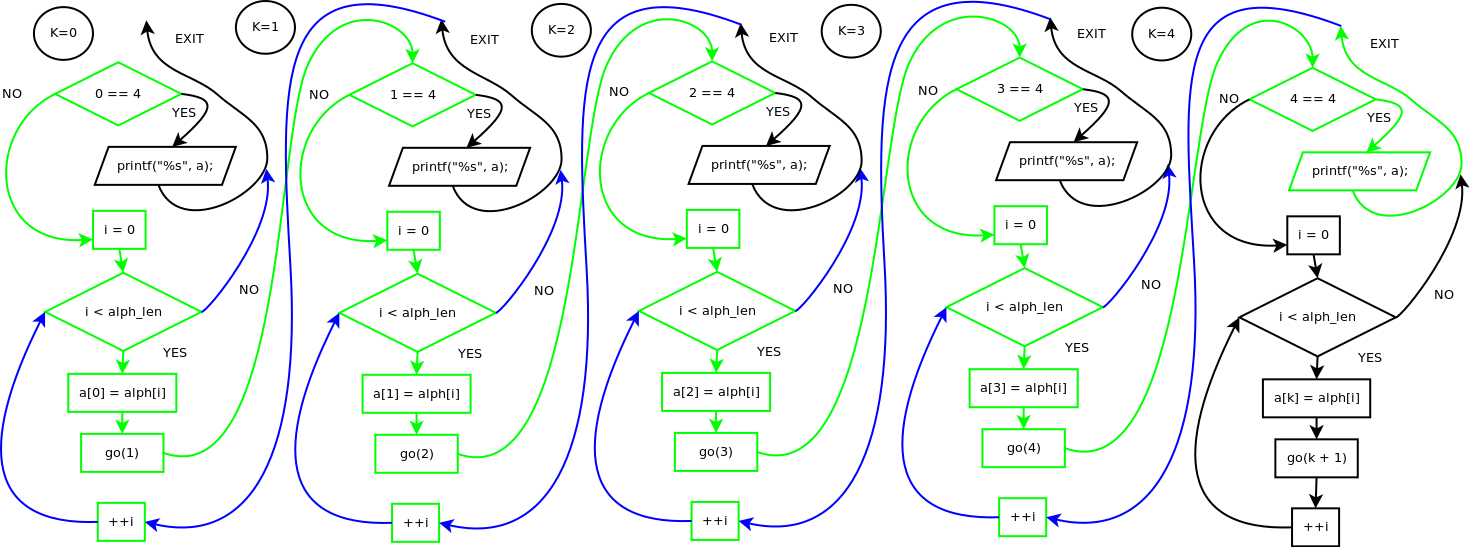
The following flowchart depicts control flow of a program that prints all words
of length 4. Green lines mean forward pass. Blue lines mean backward pass when
the function returns to the place of its invocation. Black lines stand for
inactive paths.
Press right mouse button on the image and choose “View image” to see full size
image.
This is the synopsis of the first Linux programming lab.
The description of the problem to be solved
During the whole course one problem should be solved: restore a password
from a hash code generated by htpasswd command. The password should be restored
using several approaches:
recursive brute force,
iterative brute force,
multi threaded brute force on a machine with several CPUs,
distributed over the network brute force.
The roadmap of the course
Hello world application.
Recursive brute force solution.
Iterative brute force solution.
Multi-threaded brute force solution.
Synchronous thread per client solution.
Asynchronous thread per client solution.
Reactor implementation.
Topics covered in the first lab
Linux shell commands introduction.
Source code editor.
Hello world application.
Stages of program compilation.
Primitive Makefile for the hello world application.