Two Ways to Structure Things
I’ve come to understanding that most people organize things like if they were disassembling a car: 5 inch screws in one pile, 3 inch screws into another pile, nuts in a third pile, etc. This is the approach that comes first to our mind when we need to organize something. However it’s not the easiest way to make sense of the whole system if it’s structured this way. The whole system looks like several boxes with nuts and screws of different shapes and sizes.
Another way to do it is by structuring the whole system as interacting entities. Screws and nuts from engine go into one box. Parts for suspensions system and wheels go into another box. This way we see functioning elements instead of piles of smaller parts.
Let’s discuss each of the approaches in details below and with some examples. In this context let’s think about the whole system and several entities standing side by side or as a tree of objects. A good example would be a row of people. The first approach I call horizontal, the second - vertical.
Horizontal Slicing
The first approach thinks about this row of people as several buckets: one bucket with heads, one bucket with hands, one bucket with bodies, one bucket with legs, and one bucket with feet. Not only imagining it is unpleasing it’s also disfunctional. Parts in each of those buckets have very little, so called, cohesion. They don’t interact with each other. They are useless. They just lie in those piles.
This obviously preposterous structuring in this context finds surprisingly wide support in software engineering. People create a separate package for exceptions, a separate package for utility classes, etc. Also instead of sealing logic inside of one class it gets spread among several classes. This approach leaves little room for encapsulation. Classes and packages have to make every its member public, because everyone outside this package or class needs to interact with their members. Setters and getters are considered the summit of encapsulation in such an environment.
The only argument in favour of this approach is that it’s obvious how to use it. It may have place if these moving parts are already in a relatively small box. One box for engine and then smaller boxes inside this one for engine’s screws and nuts.
Vertical Slicing
The other approach I would call vertical slicing. Vertical because it thinks about a row of humans as several buckets - human one, human two, human three. These bodies can’t interact with each other by any means other than defined by public interfaces for these bodies. The liver of one body doesn’t interact with the heart of another body.
Thinking about your classes and packages as living creatures rather than a buckets for screws and nuts helps a lot with encapsulation of the classes. The internal state of those classes can be hidden by conventional java’s access control modifiers.
If all the moving parts of one entity are colocated in the same package it’s easier to find them as you are reading the code.
Each package or class in this approach should be as a small library that provides functions and has a public interface. When I’m writing code using this approach I’m asking myself whether I can extract this package into a library right now. Once I actually need to extract a library from the project is easy to do so.
Other Areas
It’s interesting that this idea is also applicable in other areas of software engineering. Scrum advocates for vertical slicing of teams. Scrum teams are supposed to be cross functional and cut through all layers of the product, so, that one team can deliver any functionality. It’s also a popular tendency to slice teams horizontally. It leads to enormous amount of dependencies between teams and chaos when delivering a feature that has parts in each of the layers.
Examples
Let’s take a look at some of examples when the choice between these two approaches is not particularly obvious, but very important.
AST Translation
A perfect case when people get easily confused how to group classes in packages is translation of an AST. If you have an application and different parts of it need to translate this tree into different things then you naturally get an interface for Visitor for this AST. The tendency to put alike with alike leads to a confusion. Should implementations of the Visitor interface be stored near AST definition or near the services that use these implementations.
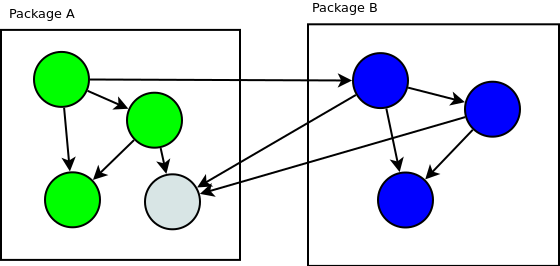
When this question arises I’m thinking about the dependencies that each class has on other classes as lines between classes. When we move classes from package to package we want to minimise the number of lines crossing the boundary of packages.
Three dependencies go through the boundary.
Two dependencies go through the boundary.
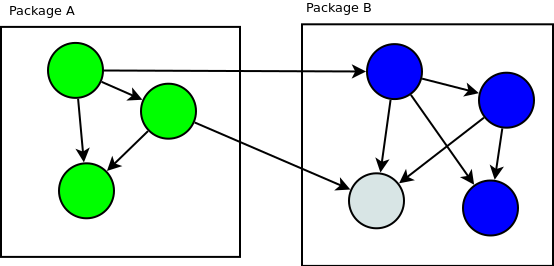
In this particular case thinking about this AST tree as a library helps a lot. The interface Visitor should be stored near the AST tree structures in a separate package and the implementations of this Visitor interface should be stored where they are used. It also minimizes the number of dependencies going through the boundary.
Configuration Beans in Spring
Engineers also tend to put all bean declarations in one configuration bean at the top level of their applications. Here I can say that if the classes inside the package don’t rely on IOC container then it’s a perfectly normal practice, because they don’t depend on the defined beans and the main application considers these classes as plain java objects.
However if the classes inside the package expect some IOC container to be in place then it makes sense to put another configuration class inside the package because it helps with understanding how classes will be wired together.
P.S.
After writing this post I google on this topic and found surprisingly many similar posts:
[http://www.markhneedham.com/blog/2012/02/20/coding-packaging-by-vertical-slice/] [https://simpleprogrammer.com/understanding-the-vertical-slice/]
This link has even more ways to structure code. What I call horizontal is called by kind in this blog: [https://medium.com/@msandin/strategies-for-organizing-code-2c9d690b6f33]